Relational Database View
Relational Database View takes snapshot of selected databases. After snapshot is taken the database connection is closed and snapshot is used for most of Relational Database View’s functionality. The snapshot can be saved to a file.
For example, from the first diagram of titles table you can tell that the table has two indexes – unique clustered on title_id, and non-unique on title. Column title_id is a primary key, that is referenced in tables roysched, sales and titleauthor. Column pub_id is a foreign key that references pub_id in publishers table. Column title_id is of tid type, which is defined as nvarchar(6).
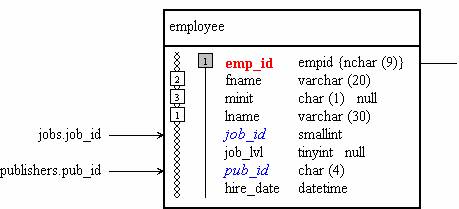
The second diagram shows employee table, that has two indexes, - non-unique clustered on lname, minit, fname (the number inside square show the column number in the index), and unique on epm_id. Column epm_id is primary key, but it is not referenced in any table. Column job_id is a foreign key, that references job_id in jobs table. Column pub_id is another foreign key – it references pub_id in publishers table.

Supported RDBMS: Microsoft SQL Server 6.5 and up, Sybase 9 and up, Oracle, DB2
|
· Relational Database View allows working off-line using saved database snapshot. |
|
· It has a powerful regular expression based search within database schema. The search is performed within table or column names, text of view definitions or the text of stored procedures. The search can be done within an entire server, one database, object category (e.g., stored procedures), individual object. You can also search within object dependencies.
|
|
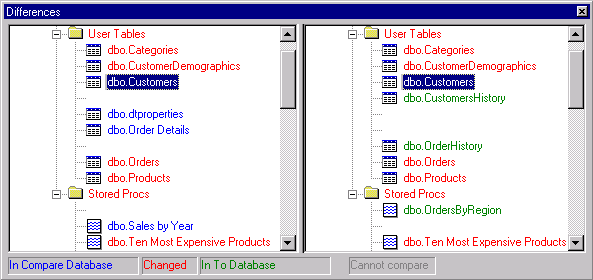
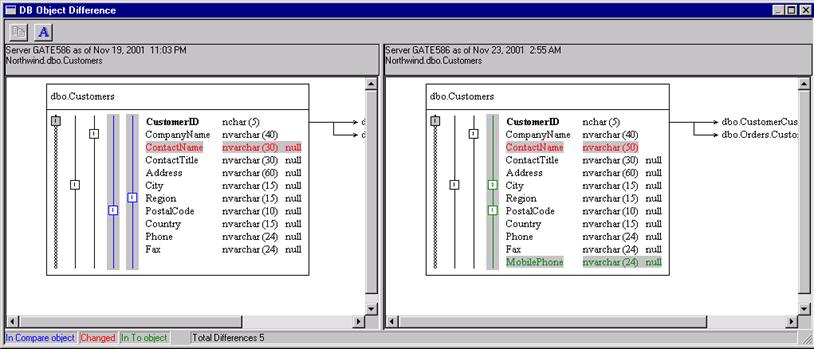
· You can compare schemas of objects, object categories, databases or servers. When comparing tables index changes are taken into consideration.
|
|
|
|
· Relational Database View shows object dependencies across databases |
|
· The diagrams can be generated in HTML format, or copied to a clipboard to create custom documentation |

Relational Database View is sold on a per-site basis. Contact us for pricing.
![]() Download your trial version now!
Download your trial version now!